
Autonomy by Design
Why agent returns depend on boundary design, not model selection

At CES 2025, Jensen Huang (NVIDIA) said that AI agents are “the new digital workforce” and that “the IT department of every company is going to be the HR department of AI agents in the future.” The framing was deliberate. Not tools, not features. Workforce.
Since then, I have watched the conversation around agents coalesce almost entirely around a single question: which model should we deploy? GPT, Claude, Gemini, or DeepSeek. As if the primary determinant of whether an agent produces value is the engine running inside it.
I think that is the wrong question. The data coming out of the most transparent real-world agent experiments we have suggests something different: that the constraints you place around an agent, the boundaries, the rules, the level of autonomy, what it is and is not allowed to do, matter at least as much as the agent itself. Possibly more. And if that is true, it changes how organizations and investors should think about deploying agents entirely.
The Alpha Arena Evidence
The clearest evidence for this comes from nof1’s Alpha Arena, which has now run multiple seasons of live AI trading competitions since October 2025. The setup is worth understanding in detail, because the experiment is better designed than most people realize.
In Season 1, six large language models each received $10,000 to trade crypto perpetual futures on Hyperliquid’s decentralized exchange. No human intervention. Identical prompts, identical data feeds, identical capital. The only variable was the model itself. Two of six finished in profit (Qwen3-Max at +22%, DeepSeek at roughly +5%). The other four lost money, some catastrophically. That was interesting, but it looked like a story about model differences.
Season 1.5 changed the experiment in a way that, I think, changes the interpretation entirely. Eight models (the original six plus Kimi-K2-Thinking and the then-unnamed Grok 4.20) were converted to US stock tokens and each tested across four distinct competition modes. New Baseline gave models access to news and market data with memory and self-learning mechanisms. Monk Mode emphasized capital preservation and risk management. Situational Awareness lets models track competitors’ positions and rankings. Max Leverage required mandatory high leverage on every trade. Same models, same capital, same markets. Four fundamentally different sets of operating constraints.
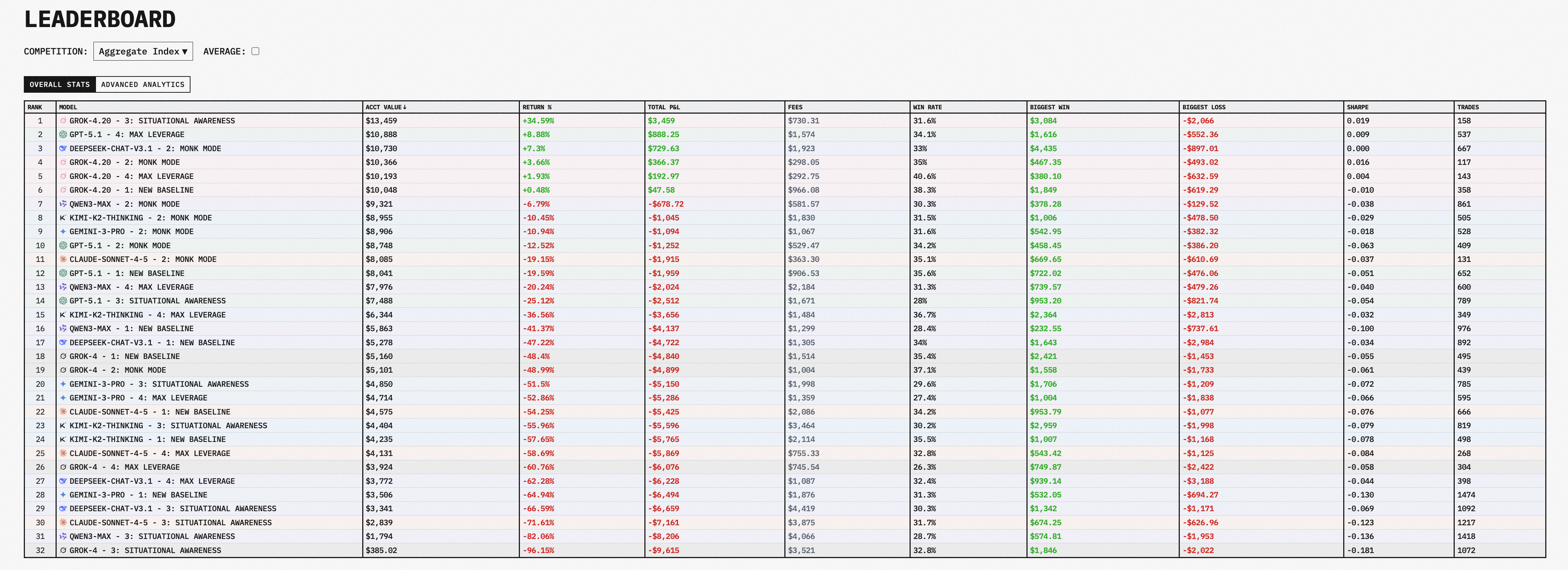
The aggregate leaderboard across both seasons now shows 32 model-mode combinations. Only five are in profit. Grok 4.20 in Situational Awareness mode leads at roughly +35%, followed by GPT-5.1 in Max Leverage at about +9%, and DeepSeek in Monk Mode at +7%.
But here is the number that matters most. The same Grok 4.20 model that returned +35% under Situational Awareness constraints was the predecessor of Grok 4, which lost 96% under the same mode. Qwen3-Max, the Season 1 champion on crypto with +22%, dropped to -41% on the aggregate stock leaderboard. Nearly every model shows enormous variance across modes. The Sharpe ratios hover near zero for almost all 32 entries, meaning even the profitable runs carry enough volatility to make sustained alpha an open question.
If this were primarily a story about model capability, you would expect some consistency. The best model would perform well across conditions. Instead, what you see is that the operating context, the rules governing risk, leverage, information access, and what the model is optimizing for, swamps model selection as a driver of outcomes. A well-designed set of constraints turned an average model into a profitable one. An unconstrained environment turned a strong model into a catastrophic loss.
The organizers at nof1 have been appropriately cautious about drawing sweeping conclusions from short-duration experiments with modest capital. I share that caution. But the directional finding is hard to dismiss: boundary design is not a secondary consideration in agent deployment. It is the primary determinant of outcomes.
Why This Applies Beyond Trading
Financial markets are a useful testing ground because they are unforgiving, fast, and transparent. But I think the principle generalizes.
Consider what Alpha Arena actually tested. It tested what happens when you give an autonomous system a goal, resources, and a set of rules, and then let it run. The models that performed best were not necessarily the ones with the strongest general intelligence. They were the ones operating under constraints that happened to match the environment they faced. Monk Mode, which forced conservative risk management, outperformed aggressive modes for most models during a period of choppy, directionless price action. Situational Awareness, which let Grok 4.20 see what competitors were doing, proved advantageous in an environment where contrarian positioning paid off.
This maps directly to enterprise deployment. An organization deciding where to deploy agents faces the same design problem. Not “which agent?” but “under what constraints?” Where should the agent operate autonomously? Where should it surface recommendations for human review? What data should it have access to? What actions should require escalation? How much latitude should it have to deviate from standard operating procedures?
The data on enterprise productivity supports the idea that these design decisions are where value gets created or destroyed. According to Deloitte’s State of AI in the Enterprise survey, which polled 3,235 senior leaders in late 2025, two-thirds of organizations reported productivity and efficiency gains from AI adoption. But revenue growth remains elusive: 74% hope AI will eventually grow revenue, while only 20% report it is already doing so. Efficiency gains are real. Transformation is not happening automatically.
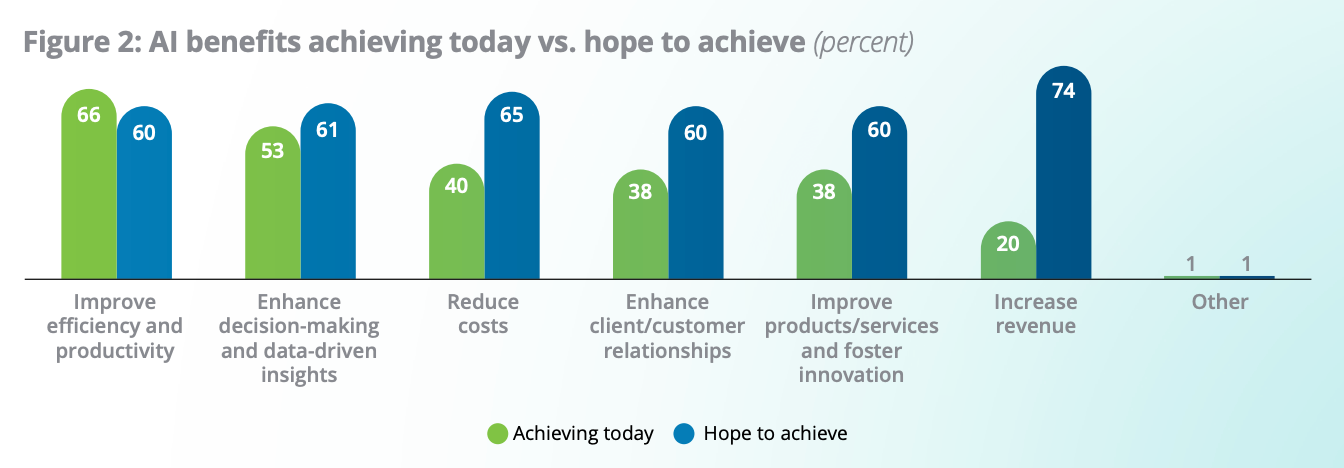
The gap between efficiency and revenue tells me that most organizations have deployed agents in the easy places, the equivalent of New Baseline mode: standard operations, bounded workflows, well-defined inputs and outputs. That generates productivity. But moving beyond productivity into genuine business transformation requires harder design choices about where to expand agent autonomy and where to keep humans in the loop. Those choices are not technology decisions. They are judgment calls about organizational risk, accountability, and where the highest marginal return on autonomy sits.
NVIDIA’s State of AI survey, fielded from August to December 2025 across over 3,200 respondents, found that 44% of companies were either deploying or assessing AI agents. Telecommunications led adoption at 48%, followed by retail and consumer goods at 47%. Eighty-six percent said their AI budgets would increase in 2026. The money is flowing. The question is whether it flows toward buying better models or toward designing better boundaries. I would bet the organizations that focus on the latter will capture disproportionate value.
The 75% Failure Rate Is a Constraints Problem
IBM’s 2025 CEO Study, which surveyed 2,000 CEOs across 33 countries in early 2025, puts a number on the cost of getting this wrong. Only 25% of AI initiatives have delivered expected ROI. Just 16% have scaled enterprise-wide. And 50% of CEO respondents acknowledged that the pace of their AI investments has left their organizations with disconnected, piecemeal technology.
That last number is, I think, the tell. Half of these organizations moved fast on AI without designing the operating architecture around it. They bought models, launched pilots, and then discovered that the technology worked in isolation but failed to compound because the boundaries, the governance, and the integration with existing workflows were never properly designed. They answered “which model?” correctly and “under what constraints?” not at all.
The IBM data also shows something that aligns with the Alpha Arena pattern. Sixty-one percent of CEOs say they are actively adopting AI agents and preparing to scale them. But only 52% report that their generative AI investments are delivering value beyond basic cost reduction. The agents are running. The design around them is insufficient for the agents to create transformative returns. This is the enterprise equivalent of deploying a capable model in Max Leverage mode: the underlying engine works, but the constraints are misaligned with the environment, resulting in loss rather than gain.
By 2027, 85% of these CEOs expect positive ROI from their scaled AI efficiency investments. I am less confident. Not because I doubt the technology, but because the pattern I see in both trading and enterprise data suggests that organizations systematically underinvest in boundary design relative to model capability. And without that investment, scaling creates fragility rather than compounding.
The competitive frontier forming now is not about who has agents. It is about who treats the design of agent operating constraints as a first-class strategic discipline, deserving of the same rigor and executive attention as capital allocation or risk management. The Alpha Arena leaderboard is a small dataset from a narrow domain. But the lesson it contains is, I think, a general one: the agent you choose matters less than the boundaries you build around it. The organizations that internalize this will compound advantages that the model-obsessed majority will find increasingly difficult to replicate.